
На секцию микропроцессорных технологий принимаются научные работы, посвященные архитектуре универсальных и специализированных вычислительных систем; САПР элементов и узлов; проектированию кристаллов; системному программированию; операционным системам, компиляторам.
Формат проведения: онлайн
Рабочий язык: русский
Дата проведения: 5 и 6 апреля 2023 г., с 15:00 часов

Тема работы возникла при разработке AOT кросс-компилятора, одной из проблемой которого является определение констант, зависящих от таргет-платформы, например смещения полей в классах, размеры самих классов и т.д.
В результате работы разработан API предоставляющий интерфейс к платформо-зависимым константам.
Данный модуль интегрирован в open-source проект и имеет документацию:
https://gitee.com/openharmony-sig/arkcompiler_runtime_core/blob/master/docs/cross-values.md

Работа была начата ещё в бакалавриате и посвящена исследованию существующих методов детекции полосы движения и разработке собственной системы, отвечающей многочисленным требованиям по качеству и производительности.

Основной задачей данного исследования было выяснить, каковы различия между скоростью сборки приложений на базе инфраструктуры LLVM с применением межмодульной оптимизации и без неё, а также оценить, насколько эффективна межмодульная оптимизация.

Данная работа посвящена улучшению оптимизации TermFoldingCondition в рамках пасса LoopStrengthReduction (LSR) в компиляторе LLVM. Благодаря этому алгоритму LSR может не только заменять дорогостоящие операции с индуктивными переменными на более дешёвые, но и объединять фи-узлы.
Разберём работу этой оптимизации, предлагаемые улучшения, ускорение алгоритма std::find_if и повышение производительности на тестах Spec-2006.
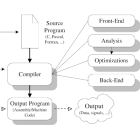
В данной работе рассмотрены существующие подходы к оптимизации косвенных вызовов процедур, показаны возможности применения анализа сигнатур процедур для этой оптимизации на примере компилятора GCC.

В работе предложен метод подбора оптимальной конфигурации микроархитектуры, позволяющий варьировать большое число параметров малого порядка и эффективнее (по сравнению с существующими подходами) оценивать влияние этих параметров на производительность процессора.

Данная работа посвящена оптимизации параллелизма на уровне инструкций. Основой предлагаемой техники является использование данных профилирования и информации о независимости секций кода.

Задачей нашего иследования было проверить, можно ли увеличить качество аппаратной предвыборки при помощи простых моделей машинного обчуения, в частности, с применением наивного байесовского классификатора. Также задачей было оценить, целесообразно ли применять модели машинного обчения и могут ли они дать прирост производительности процессора.

В работе исследовались модели сжатия данных на стадии инструментации. Подход является новым, т.к. специализируется на средствах динамического бинарного анализа. Это накладывает дополнительные ограничения на реализацию алгоритмов. Одним из них является общий размер инструментации. От нее зависит производительность и корректность работы инспектируемых приложений. Разработанные алгоритмы на основе дельта-кодирования и усечения старших разрядов позволили ускорить работу DBI-клиента в 1.16 раз.

В данной работе предлагается система для сверхбыстрой реализации в ПЛИС/ASIC сложных математических алгоритмов обработки видеокадров в реальном времени, основанная на трансляции из высокоуровневого языка программирования в язык SystemVerilog. Эффективность разработки с помощью инструмента продемонстрирована на двух алгоритмах, использующих тональное отображение и линейную свертку.

В работе предложены методы индексации хронологических данных, позволяющие индексировать данные в режиме отложенной записи (что важно для высокой пропускной способности записи во внешнюю память) и эффективно осуществлять запросы по диапазону ключа при заданном моменте времени, а также запросы объектов, удовлетворяющих произвольно сложной булевой формуле от булевых признаков.

В настоящей работе автором предложена поведенческая модель синхронного импульсного понижающего преобразователя напряжения. Для описания функциональных блоков поведенческой модели использовался язык Verilog-A. Ближайшими аналогами рассматриваемого преобразователя являются микросхемы LM25117/Q1, XRP7675 и SPPL12420RH.

Разработка и исследование аппаратной системы мониторинга производительности для вычислительной системы

Качественно прописанная спецификация позволяет эффективно и корректно пользоваться описаниями команд и их сигнатурами для генерации кода, проверять входные и выходные типы данных, что необходимо для абстрактной верификации.

В настоящей работе описана концепция ЭТТ для печатных плат, разобран алгоритм работы устройства и получены некоторые численные характеристики в эксперименте.

В работе исследована проблема консистентности таблиц переходов на архитектуре ARM при применении бинарных оптимизаций, влияющих на расположение программного кода. Предложен алгоритм анализа и исправления ошибок, возникающих в таблицах переходов при данных оптимизациях.

В качестве одной из технологий анализа работы приложения используется динамическая бинарная инструментация. Одно из её ключевых предназначений – сбор информации о работе приложений.
По мере роста сложности задач возникает необходимость профилирования трасс исполнения, чтобы проанализировать приложение на некотором уровне представления и представить результат в понятной для человека форме.
В ходе данной работы был разработан профилировщик трасс приложений под ARM архитектуру.

Рассмотрены инструменты для отладки и верификации бинарного оптимизатора BOLT(Binary Optimization and Layout Tool) с помощью модификации и генерации тестовой профильной информации.

Данная работа посвящена разработке СнК(системы на кристалле) на базе процессорного ядра SCR1 с возможностью взаимодействия с интерфейсом GPIO, а также контроллерами UART, SPI и модулем памяти SRAM. Рассмотрен полный путь создания СнК от стадии проработки Архитектуры до имплементации физического дизайна.
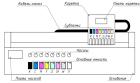
Данная работа посвящена разработке системы управления подачей чернил (СУПЧ), являющейся одной из ключевых составляющих широкоформатного принтера. Задачей СУПЧ является обеспечение бесперебойной подачи чернил (которые представляют собой жидкий фотополимер с ультрафиолетовым отверждением) к печатающим головкам принтера, а также реагирование на аварийные ситуации, включая сигнализацию о них.

Задачей нашего исследования было проверить, можно ли увеличить качество аппаратной предвыборки при помощи простых моделей машинного обучения, в частности, с применением наивного байесовского классификатора. Также задачей было оценить, целесообразно ли применять модели машинного обучения и могут ли они дать прирост производительности процессора.

В динамических сценах для ускорения трассировки лучей используют ускоряющие структуры, одной из которых является двух-уровневое BVH-дерево. Одним из существенных недостатков этой структуры является перекрытие ограничивающих обьемов различных обьектов сцены, что существенно замедляет трассировку в таких областях. В данной работе предложен один из алгоритмов по уменьшению влияния этого недостатка.

Данная работа посвящена исследованию выборочных реализаций архитектуры RISC-V, синтезированных с использованием современных инструментов синтеза цифровых схем, таких как открытый OpenLane и коммерческий Design Compiler. Основная задача исследования заключается в анализе характеристик полученных ядер, с целью оценки методов оптимизации процессов синтеза обоих инструментов.

В результате работы получен новый инструмент для симплификации моделей, также произведены сравнения упрощённых несколькими методами (с применением традииционных алгоритмов и с применением машинного обучения и графовых нейронных сетей) 3D моделей, используемых в современной компьютерной графике, с исходными.